
When working with Databend, you don't bother maintaining indexes. Databend takes advantage of these indexing techniques to automatically build and manage indexes on the fly:
- Min/Max index
- Bloom index
- Cluster key
Min/Max Index
Min/Max Index is the key indexing technique for OLAP databases. Databend Fuse Engine uses it as the main indexing method to build indexes and store them in snapshots, segments, and blocks. The following shows how the Min/Max Index works for a table in Databend.
First, use SHOW CREATE TABLE to find the initial snapshot file created for the table:
show create table ontime(
`Year` INT, -- First column
...
) ENGINE=FUSE SNAPSHOT_LOCATION='1/458/_ss/71b460c61fa943d1a391d3118ebd984c_v1.json'
Downdoad and open the snapshot file with VSCODE:
{
"format_version": 1,
"snapshot_id": "71b460c6-1fa9-43d1-a391-d3118ebd984c",
"timestamp": "2022-11-29T03:44:03.419194Z",
"prev_snapshot_id": null,
"schema": {
"fields": [
... -- Field definitions
],
"metadata": {}
},
"summary": {
"row_count": 90673588,
"block_count": 200,
"perfect_block_count": 0,
"uncompressed_byte_size": 65821591614,
"compressed_byte_size": 2761791374,
"index_size": 1194623,
"col_stats": {
...
"0": { -- Min/Max indexes for the first column 'Year' in the table
"min": {
"Int64": 1987
},
"max": {
"Int64": 2004
},
"null_count": 0,
"in_memory_size": 362694352,
"distinct_of_values": 0
},
...
},
},
"segments": [
...
[
"1/458/_sg/ddccbb022ba74387be0b41eefd16bbbe_v1.json",
1
],
...
],
"cluster_key_meta": null
}
The file above indicates that the min value of the first column is 1987 and the max is 2004. The indexes in a snapshot file can tell you whether the data you want to retrieve exists in the table. For example, no data would be returned for the following query if Databend cannot find a matching Min/Max interval in all snapshots:
select avg(DepDelay) from ontime where Year='2003';
Databend Fuse Engine stores the most important indexes in segment files. At the end of a snashot file, you can find information about which segments are related to the snapshot. Here's a sample segment file:
{
"format_version":1,
"blocks":[
{ -- block ...
...
"row_count": 556984,
"block_size": 405612604,
"file_size": 25302413,
"col_stats": {
...
"0": {
"min": {
"Int64": 2003
},
"max": {
"Int64": 2003
},
"null_count": 0,
"in_memory_size": 2227936,
"distinct_of_values": 1
},
...
},
"col_metas": {
-- Used to record the start position and length of each column
},
"cluster_stats": null,
"location": [
"1/458/_b/e4f3795c79004f22b80ed5ee821edf23_v0.parquet",
0
],
"bloom_filter_index_location": [
"1/458/_i_b_v2/e4f3795c79004f22b80ed5ee821edf23_v2.parquet",
2
],
"bloom_filter_index_size": 60207,
"compression": "Lz4Raw"
...
}
],
"summary": {
"row_count": 11243809,
"block_count": 25,
"perfect_block_count": 25,
"uncompressed_byte_size": 8163837349,
"compressed_byte_size": 339392734,
"index_size": 1200133,
"col_stats": {
...
"0": {
"min": {
"Int64": 1988
},
"max": {
"Int64": 2003
},
"null_count": 0,
"in_memory_size": 44975236,
"distinct_of_values": 0
},
...
}
}
}
From the sample above, we can see that a segment file contains its own Min/Max index information. So does a block file. The Min/Max indexes are layered and distributed among snapshots, segments, and blocks like this:

When retrieving data for a query, Databend starts from the snapshot indexes and locates the corresponding segment by matching the Min/Max interval. Then, it looks up the indexes in the segment file to find the block where the required data is stored and reads data from the block file with information about the start position from col_metas. So Databend literally processes a query by finding the right segments and blocks with the Min/Max Index.
Bloom Index
For queries requiring an exact string match, Databend uses the Min/Max Index to find the right block first, and then locates the offsets with the bloom index information in bloom_filter_index_location to retrieve data from the block.
For more information about the Bloom Index, see https://databend.rs/blog/xor-filter.
Cluster Key
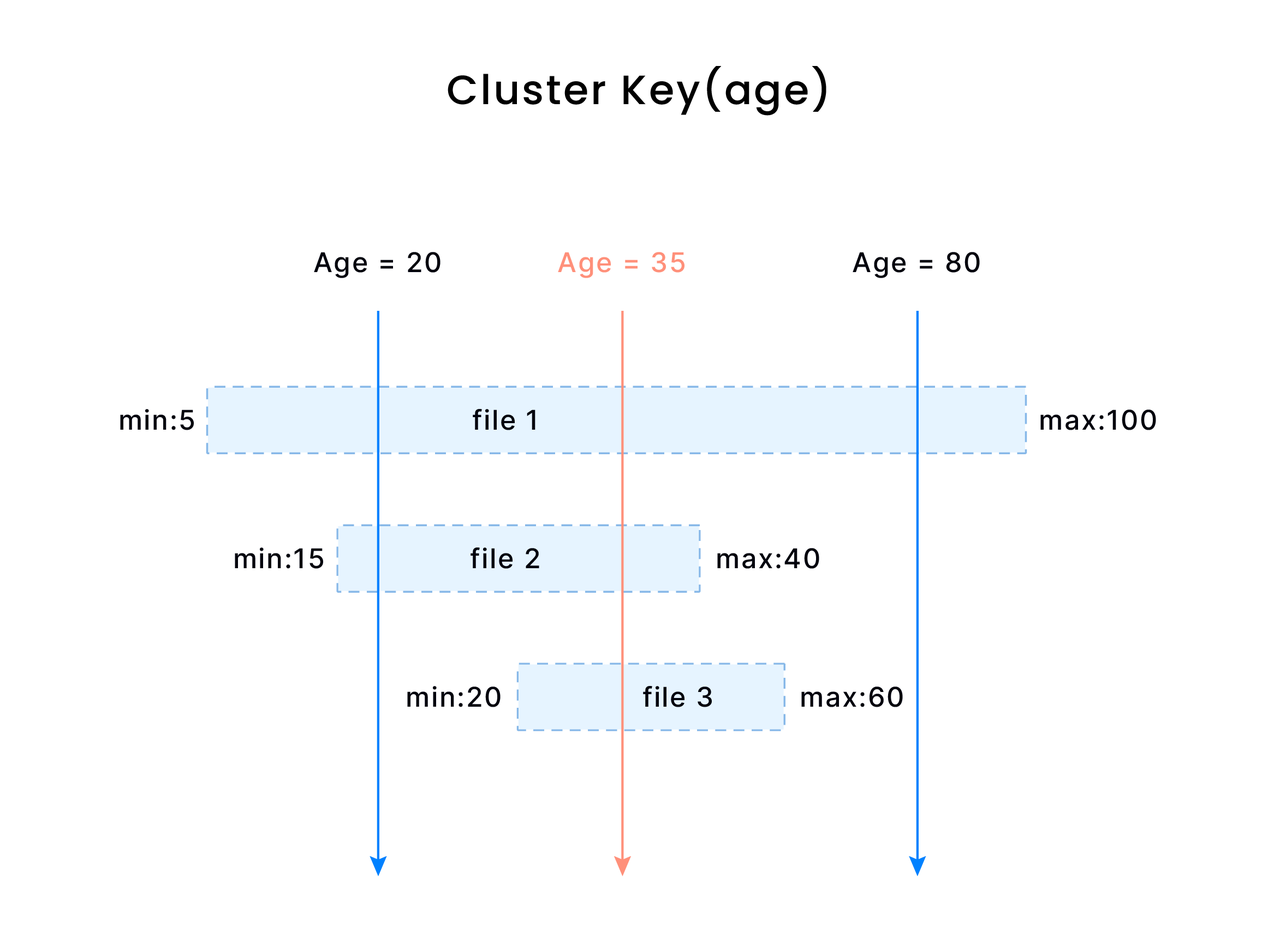
The Min/Max Index seems to work perfectly for Databend, but in fact, data is usually written into a table out of order. As a result, segments and blocks might be created with overlapped Min/Max intervals.
For example, you need to access up to three parquet files for a query condition like Age = 20 & Age = 35. If Age is set as the cluster key, Databend will sort the data by the Age column and combine as many small parquet files as possible.
For more information about the cluster key, see https://databend.rs/doc/sql-commands/ddl/clusterkey/.